

Introduction to Data Science
Data science is to study large amount of data to predict and build models with the help of machine learning and to help in product or a business development.
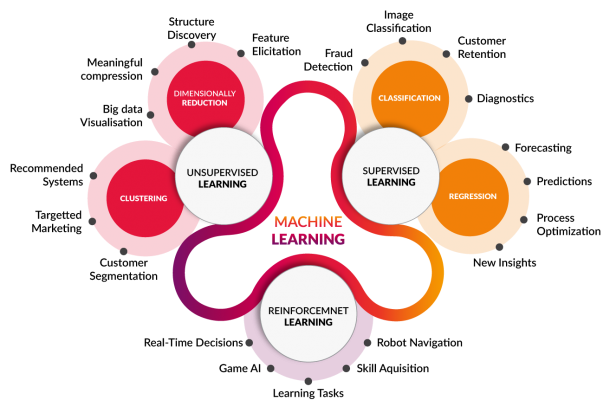
Machine learning in a nut sheel
Machine learning is to collect the data, analyze the historical data, find patterns and create algorithms, build a model by recoginizing patterns, apply to the business model. The application supplies new data to see if it matches known patterns.
Some of the examples of Machine learning is, auto organization of your email in box, Amazon or Flipkart sales recommendation, Auto bots chatting system, Cars navigation system, Google Maps recommendations, Search Box auto completes, facebook likes etc.,
Model
A model runs on algorithms and data to learn and then make predictions
Data feeds algorithms and algorithms train models
All the answers out of model predicts the answer based on our relevant question with our data.
Types of data
Data - > Quanitative-> Categorical or qualitative
Quantitative -> Descrete & Continuous
Qualitative - > Nominal & Ordinal

Continous (Measured) Discrete
- Height of a child Number of languages spoken
- Length of Leaf Number of books in the shelf
- Speed of a train Number of kids in a school
Nominal: Some thing we cannot compare with each category
Ordinal: Something which can be compared with each category
Training data and testing data
Dividing the 100% data to 70% (Let's say..) is the training data. Where as the remaining 30% data is used to predict the complete model is a testing data.
Evaluation would be done to decide the model is good or bad after testing the data and building a model.
If 3 out of 4 testings failed then our model is failed. Then, change the algorithm and re-build the model.

Life Cycle of Data Science Project

1) Train the Model with training data (70% Data)
2) Test the model with test data (30% Data)
3) Train the model with complete data(100% - eg: 19th June 2021 to 18th June 2022)
4) Validate the model
5) Deploy the Model in Production (eg: 19th June 2022)
6) Monitor the Model
7) Retrain the Model (When there is a drop in model performance)
Then we need to retrain the model.
Reasons for poor performance might be (Data Drift, Model Drift, Concept Drift)
Steps to retrain the model:
- 1) Data append (old(ex: 19th June 2021 to 18th June 2022 + New data (ex: 19th 2022 to 18th June 2023))
- 2) Data change
- 3) Data Cleaning Change
- 4) Algorithm change
- 5) Algorithm parameter change
Share all your opinions about this introduction! Awaiting for your replies here..